
A few months ago, my self-hosted Nextcloud instance went offline. It wasn’t due to a malfunctioning hard drive or a poorly designed network loop. The issue was caused by an HAProxy VM that became unresponsive. Until I went to the server and performed a hard reboot, I couldn’t access any of my services. That experience led me to implement redundancy into my environment to avoid relying on a single-point-of-failure. While the documentation provided by HAProxy is good, I have had difficulty connecting all the essential dots on all the various components when faced with a tight deadline. This post provides you with the specific configuration steps that I currently use for setting up high availability HAProxy Keepalived without any pain.
Quick Summary
- The final solution will consist of two Linux-load-balancing nodes with one shared floating IP.
- Keepalived is responsible for VRRP failover, while HAProxy is responsible for the actual layer 7 traffic routing.
- You will see working configurations for both HAProxy and Keepalived, the kernel trick that prevents HAProxy from failing to start, and my method of avoiding split-brain scenarios before they become problematic.
- You will find all the commands and output logs listed in this article are from my personal homelab notes.
Understanding Linux Load Balancer Architecture
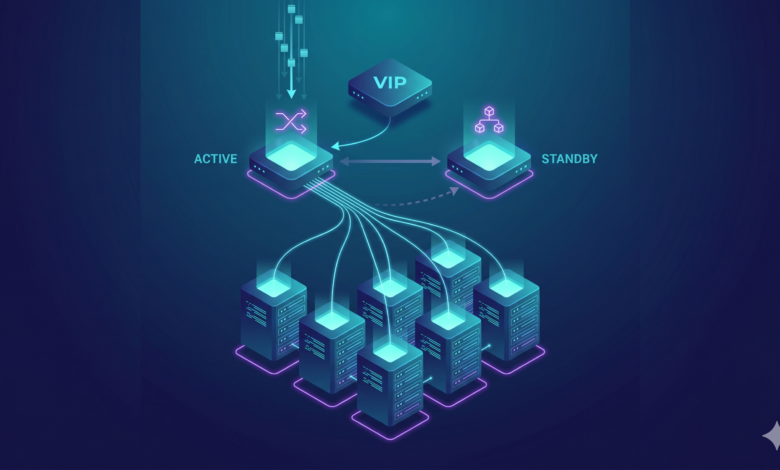
Before you create any configuration files, it is extremely important that you fully understand how the components communicate with each other. This is a Linux Load Balancer Architecture defined with two independent and state-less Daemons.
The Role of a Highly Available Reverse Proxy
An HAProxy Reverse Proxy is much more than just a tool for load-balancing distribution of client traffic.If the proxy fails, another proxy should take over and provide the same IP and routing rules to give continuity to the DNS and the clients. Without this continuity in place, the DNS entries of type A will need to be updated manually, creating a chaotic situation with your phone receiving numerous calls from clients.
How VRRP Enables Seamless Active-Passive Failover
VRRP allows you to use a single virtual IP for both servers while allowing them to operate independently by designating one of them as the primary node and keeping the other available as a standby node. The standby node will listen for multicast advertisements from the main server, and if it does not receive these for a couple of seconds, it can assume the IP and respond to ARP requests for it. In the following configuration of vrrp keepalived, you will set the timing and priorities of these events.
Visualizing the Data Flow in a Clustered Environment
Imagine you have two load balancer nodes, lb01 and lb02, each with its own real IP (.11 and .12, respectively). Both of these nodes will be able to provide the virtual IP (.10) only when configuration is done using Keepalived. All traffic will always hit the virtual IP (.10) First, that is the only time that a client’s actual real IP will be seen by the backend servers; however, they will not care which load balancer is active, as that’s why the setup exists.
Environment Prerequisites and Network Planning
Your network settings should not be determined on instinct, and you should not rely on HAProxy binding to an IP address that does not currently exist on the local interface. Therefore, you should determine the OS settings in advance.
Provisioning Target Nodes and the Floating IP Keepalived Uses
For target nodes, I am using two light-weight Debian VM’s with one vNIC (virtual NIC) per machine. The static IP’s are real, and I decided to use my own free IP, in the same subnet, as the floating IP address that Keepalived will manage for failover purposes, without involving any of my network team. Since the IP is just for Keepalived’s own configuration, it does not appear assigned to any other machine in our environment (yet).
Why I ultimately chose this route
Initially, I attempted to use the Corosync/Pacemaker approach for high-availability cluster management. This method worked for me, however, when adding a new backend server to my cluster, I needed to create a separate XML config file for Pacemaker and for each machine in the cluster. After that, I had to hope and wish for everything to work correctly. Keepalived was a much simpler alternative as it only manages VIP’s (virtual IP’s) and does not rely on any complex clustering mechanism or fencing. Keepalived’s configuration is also easy to memorize and is perfect for a 2-node active-passive HA cluster.
Enabling IP Non-Local Bind in the Linux Kernel
HAProxy will fail to start on the second node because it has not been assigned the shared VIP on the underlying interface. This restriction is inherently built into the Linux kernel. The restriction can be lifted by modifying one sysctl entry.
# sysctl net.ipv4.ip_nonlocal_bind
net.ipv4.ip_nonlocal_bind = 0 <-- currently rejecting foreign IPs
# echo 'net.ipv4.ip_nonlocal_bind=1' >> /etc/sysctl.conf
# sysctl -p
net.ipv4.ip_nonlocal_bind = 1 <-- now allows binding to VIP before it's local
This line ensures that you do not need to write any complicated startup scripts for HAProxy to utilize the VIP on the second node. When you have done this once, make the modification persistent.
Configuring Firewall Rules for VRRP Multicast Traffic
VRRP uses the protocol number: 112 and multicast address: 224.0.0.18. If you have a filtering rule in your iptables that drops certain protocols, then you will likely break your VRRP failover silently if you do not permit VRRP traffic to flow through your firewall.
# iptables -A INPUT -p 112 -s 192.168.1.0/24 -d 224.0.0.18 -j ACCEPT
# iptables -A OUTPUT -p 112 -d 224.0.0.18 -j ACCEPT
The rule set above allows for VRRP traffic from the local LAN network and VRRP advertisements sent back to the originating node. Do not forget to modify the source subnet in the above example to your own subnet.
How to Setup HAProxy Keepalived High Availability
At this stage, you have installed the daemon software packages required for High Availability. You have two configuration files that will allow Keepalived and HAProxy to work together effectively.
Installing the Required Daemon Packages
Keepalived and HAProxy are standard software packages and are available in nearly all distribution package repositories.
# apt update && apt install haproxy keepalived -y
Reading package lists... Done
...
Setting up keepalived (1:2.2.8-1) ...
Setting up haproxy (2.6.12-1) ...
Do Not start the daemons yet. Complete the configuration before beginning to start the services. Do not be tempted to install your Keepalived and HAProxy configurations first then the daemon software package.
Structuring the /etc/keepalived/keepalived.conf File
The /etc/keepalived/keepalived.conf file is the main configuration file for Keepalived and must be set up correctly for High Availability and for VIP Redundancy. Below is an example of how the configuration will look for both the master and backup nodes (excluding global configuration definitions).
For the master node (lb01):
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100 <-- higher wins
advert_int 1
authentication {
auth_type PASS
auth_pass s3cret
}
virtual_ipaddress {
192.168.1.10/24
}
}
For the backup node (lb02):
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90 <-- lower priority means backup
advert_int 1
authentication {
auth_type PASS
auth_pass s3cret
}
virtual_ipaddress {
192.168.1.10/24
}
}
It is very important that when configuring the virtual_router_id and password for both nodes, to use the same values. I have spent many hours trying to troubleshoot a configuration problem because one of the nodes had a virtual_router_id of 51 and the other had a virtual_router_id of 52. You will also find a complete list of configurable values within the Keepalived manual, in case you want to modify the advertisement interval or set up Unicast Fallback.
Writing the HAProxy Failover Setup Configuration
HAProxy does not know it is part of a cluster. We tell HAProxy to bind to the Virtual IP (VIP), and by enabling the sysctl parameter net.ipv4.ip_nonlocal_bind, HAProxy will not complain because it is bound to an IP address that it does not think is a local address. Below is an example of the configuration file for HAProxy to use for failover setup.
frontend web_front
bind 192.168.1.10:80
default_backend web_servers
backend web_servers
balance roundrobin
server web01 192.168.1.21:80 check
server web02 192.168.1.22:80 check
Both lb nodes (lb01 and lb02) will be configured with the same configuration file, so that the backup node will start HAProxy, will be bound to the VIP that is not local yet, and therefore will simply sit there and not serve any traffic until it is promoted to the master by Keepalived.
Both Keepalived and HAProxy can easily determine which node is the master by checking the VIP, and which node is the backup by checking the current status of both nodes.
Verifying Cluster State and Restarting Services
Both Keepalived and HAProxy should now be enabled and both services should be started on both nodes.1. Check for VIP on Master.
# ip addr show eth0 | grep 192.168.1.10
inet 192.168.1.10/24 scope global secondary eth0
If you see this in one node only and not both nodes your cluster is healthy. Check /var/log/syslog for a message: (VI_1) Entering MASTER STATE on exactly one box.
Optimizing HAProxy Backend Routing and Health Checks
A basic round-robin backend does not provide effective routing when a backend application starts to return 500 errors but still has an open port. This is when HAProxy kicks in with a more intelligent backend route for those situations.
Implementing Layer 7 vs Layer 4 Load Balancing
If your application communicates over HTTPs, then you should implement it as Layer 7 (mode http). You can inspect request headers, rewrite paths, and use stick tables. If your application communicates over TCP without any HTTPs, you should configure it as Layer 4 (mode tcp).
backend web_servers
mode http
option httpchk GET /health
...
Instead of providing a simple TCP health check of the backend port, the httpchk line gives you a robust health check of the backend via a true HTTP request. This makes it much more reliable.
Configuring Aggressive Backend Server Health Checks
I configure my health checks to detect a backend server that has begun limping.
backend web_servers
mode http
option httpchk GET /health
http-check expect status 200 <-- fail on anything but OK
default-server inter 2s fall 3 rise 2
server web01 192.168.1.21:80 check
server web02 192.168.1.22:80 check
If a backend server returns a 503 status code three consecutive times, at 2-second intervals, HAProxy will mark the backend server as being in the DOWN status. The backend server will be marked as UP after it has passed two successful health checks. The above link HAProxy documentation on http-check provides the complete details of the different status codes you can use for your custom health checks.
Managing Session Persistence and Sticky Logging
Users must access the same backend after you sign in. To handle this, I use a cookie based stick table.
backend web_servers
...
cookie SERVERID insert indirect nocache
server web01 192.168.1.21:80 check cookie web01
server web02 192.168.1.22:80 check cookie web02
HAProxy drops a SERVERID cookie and routes subsequent requests from users that have signed in back to the same server. For most apps, there’s no requirement for shared memory or external session store.
Mitigating the VRRP Split-Brain Edge Case
When both nodes of a VRRP network see themselves as master, it creates a problem known as “split-brain.” Clients may start to see duplicate IP addresses appear in their ARP tables, and half of their sessions may drop.
Identifying Split-Brain via System Logs
To identify a split-brain failure, check the system logs for evidence that both nodes were active at the same time in that they both tried to obtain master status. Below is an example of a log snippet that would indicate a split-brain failure.
# tail -f /var/log/syslog | grep Keepalived_vrrp
lb01 Keepalived_vrrp[1123]: (VI_1) Entering MASTER STATE <-- first master
lb02 Keepalived_vrrp[1022]: (VI_1) Entering MASTER STATE <-- also master, bad
If you see the log entry Entering MASTER STATE on two machines within the same second, you have a split-brain failure. Please stop investigating and begin planning remediation on your network.
Debugging VRRP Keepalived Configuration Mismatches
Nine times out of ten, the cause of a split-brain is a mismatch of passwords or virtual_router_id. In addition, I have also seen one node stuck at higher priority due to a missing priority update on the backup node. Make sure to verify that both nodes have identical values set for the authentication block and for advert_int.
Utilizing Unicast VRRP as a Network Workaround
Some hypervisors and low-cost switches have issues processing multicast traffic, so switching to Unicast often solves this problem very quickly.
vrrp_instance VI_1 {
...
unicast_src_ip 192.168.1.11
unicast_peer {
192.168.1.12
}
...
}
Both nodes point their informs to each others IP. No multicast traffic is needed. I run Unicast in my lab because I am using a low-cost switch that has a multicast snooping bug that I didn’t want to pay for fixing.
Frequently Asked Questions
How do I force a manual failover from the master to the backup node?
Simply stop Keepalived on the master node. In less than one advert_int and a couple of skew seconds, the backup node will grab the VIP.
# systemctl stop keepalived
If you want to bring the original master node back into the backup node role, you can do so by restarting Keepalived on the original master node. It will come back onto the network with its configured priority.
Can I run HAProxy and Keepalived in an active-active load balancing configuration?
Yes! You can define multiple VRRP instances with different virtual router ids and floating IPs. You can use either DNS round-robin or Anycast to distribute the load across HAProxy and Keepalived instances. However, true active-active load balancing at the proxy layer requires session synchronization between HAProxy nodes. As this is not built-in, I do not support using active-active configurations with stateful applications unless I use shared sticky-table storage, e.g., Redis.
Why is HAProxy failing to start on my backup server without the virtual IP?
Because you did not set the sysctl net.ipv4.ip_nonlocal_bind=1. When the backup tries to bind with the VIP, it will do so in local space; it will do this after you set the sysctl and load HAProxy without the VIP.